연초, 의욕으로 가득하던 시기에 지인의 권유로 데이콘(Dacon.io)에서 주관하고 한국수력원자력에서 주최한 원자력발전소 상태판단 경진대회에 참가하게 되었다. 지인의 지인도 합류하여 팀은 총 3인으로 구성되었다. 하지만 개개인의 일정과 생업으로 인해서 진행은 각자 하되, 진행사항이나 인사이트 등은 수시로 공유하고, 제출은 팀의 이름으로 제출하는 형식으로 진행되었다. (초기의 으쌰으쌰하던 분위기와 달리 흐지부지된 감이 없잖아 있었다. 팀당 제출횟수가 하루 3회로 제한되었기 때문에, 이럴 줄 알았으면 애초에 각자의 이름으로 혼자 해도 됐겠다 싶기도 했다. 하지만 결과론적인 총평이기 때문에 패스)
대회 개요

원자력발전소 상태 판단 대회는 한국수력원자력(주)에서 제공한 발전소 모의 운전 데이터를 통해 원자력 발전소의 상태를 판단하는 것이 태스크로 주어진다.
평가지표
평가 지표는 Log loss 이다. Log loss 값은 0 ~ 1 사이로 산출되며, 낮고 0에 가까울 수록 모델의 예측력이 좋음을 의미한다. (데이콘 측 평가지표 설명 영상)
$$ \text{logloss}(\cdot) = \frac{-1}{N}\sum_i^N \sum_j^M y_{ij} \log{p_{ij}} $$
데이터셋
원자력 발전소 모의 데이터는 기본적으로 828개의 발전소 운전 Train 데이터 파일과 각 파일에 부여된 198가지 상태 레이블이 매핑된 Label 파일이 주어진다. 압축을 해제하면 총 81GB에 달했다.

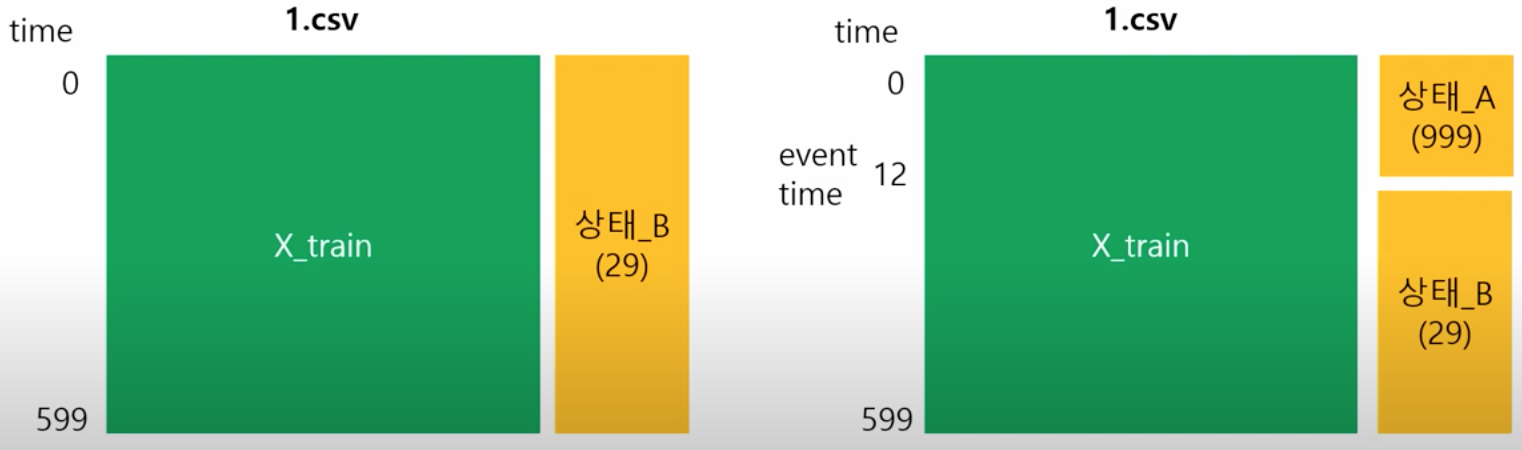
각각의 파일에 저장된 Train 데이터셋 위의 그림과 같으며, 발전소가 10분 동안 작동한, 즉 1행 당 1초 즉, 600행으로 이루어진 데이터가 주어진다. 모든 데이터셋은 발전소의 상태가 변하기 전 디폴트 상태_A(999) 와 상태가 변한 후 상태_B 데이터를 담고 있으며, 상태_A에서부터 시작된다. 데이터는 0초에서 15초 사이에서 상태가 변하기 시작한다. 따라서 데이터 상태의 변화가 0초에서 발생한다는 말은 상태_A가 없는 좌측의 데이터셋과 같고, 그 이외에는 우측과 같다고 보면 된다.
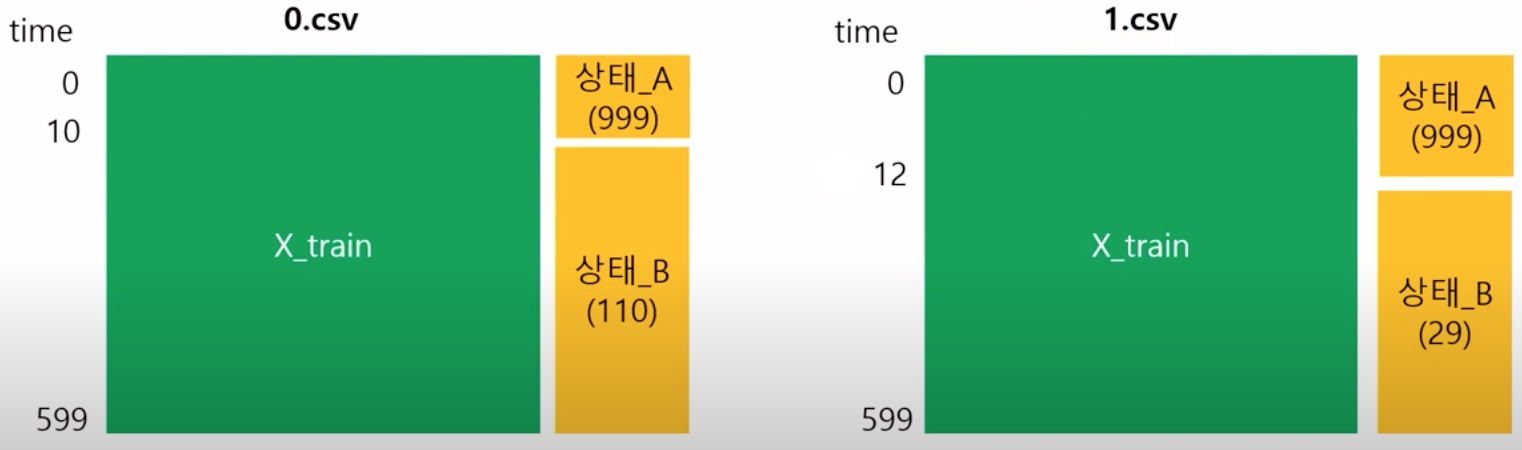
다만 위의 그림과 같이, 실제로는 몇 초부터 상태가 변하는지에 대한 정보가 주어지지 않기 때문에, 각 데이터셋이 좌측과 같은지 우측과 같은지는 한 눈에 판단이 어렵다.
데이터 전처리
EDA 과정에서 의미 있는 인사이트를 도출해내지 못 했다. 그리고 대회 경험이 적고 시간이 촉박했던 관계로, 바로 전처리에 돌입했다.
- Label이 999 인 경우 제외한다.
- 10분 간의 운전 데이터 기록 컬럼 내 unique한 값이 < 10 인 컬럼은 제외한다.
- 데이터셋 중 str타입의 데이터가 발생할 경우 NaN 치환한다.
- 마지막으로 NaN 데이터는 0으로 채운다.
- Train / Eval 데이터셋은 3:1의 비율로 분리한다.
#1
train = train[train['label']!=999].reset_index(drop=True)
train_label = train.label
train = train.drop(['id','time','label'], axis=1)
#2
with open('filter_col.txt', 'r') as filehandle:
list_ = filehandle.readlines()
list_ = [col.replace('\n', '') for col in list_]
train= train[list_]
# 3
for col in train.columns:
if train[col].dtype != 'float64':
train[col] = pd.to_numeric(train[col], errors='coerce')
#4
train = train.fillna(value=0, axis=1)
#5
X_train, X_valid = train_test_split(train, test_size = .25, random_state=42)
y_train, y_valid = train_test_split(train_label, test_size = .25, random_state=42)
모델
모델은 LightGBM을 선택했다. Tabular dataset의 분류 문제에는 나무모형 기반의 모델이 가장 적합했고, LightGBM, XGBoost, Random Forest를 초기 테스트 한 결과 LightGBM이 가장 빠르고 성능이 좋았기 때문이다.
부스팅 방법으로는 가장 기본적인 Gradient Boosted Decision Tree를 선택했다. 또한 데이터셋이 커서 연산이 큰 문제와 오버피팅을 방지하기 위해 bagging_fraction, feature_fraction 파라미터의 설정으로 데이터셋의 행과 열을 0.5 비율로 고정하여 학습 중 샘플링할 수 있도록 했다.
그 외 objective, num_class, metric과 같이 대회의 목적에 맞게 변경한 파라미터를 제외하고는 default를 가져온 것들이 대부분이다.
import lightgbm as lgb
X_train = X_train.to_numpy()
X_valid = X_valid.to_numpy()
y_train = y_train.to_numpy()
y_valid = y_valid.to_numpy()
train_data = lgb.Dataset(X_train, label=y_train) #, feature_name=X_train.columns)
valid_data = lgb.Dataset(X_valid, label=y_valid) #, feature_name=X_valid.columns)
param = {
'objective': 'multiclass',
'num_class': 198,
'boosting':'gbdt',
'num_leaves':32,
'max_depth':20,
'min_data_in_leaf':20,
'metric':'multi_logloss',
'learning_rate' : 0.01,
'verbose' : -1,
'bagging_freq' : 1,
'bagging_fraction' : 0.5,
'feature_fraction' : 0.5,
}
evals_result={}
num_round = 2000
lgbst = lgb.train(params=param,
train_set=train_data,
num_boost_round=num_round,
valid_sets=[valid_data],
evals_result=evals_result,
early_stopping_rounds=1000,
verbose_eval=10)
lgbst.save_model('model_lgb.txt', num_iteration=lgbst.best_iteration)
결과
결과는 가채점 기준 36위 / 201팀, 최종 데이터셋 기준 채점 및 중복 및 부정 제출 등의 여부가 판결 뒤 산출된 최종 순위는 16위 / 187팀를 기록했다. 전체 참가팀만 놓고 보면 1091팀이지만, 실제로 제출한 팀은 20%에 그친 것을 확인할 수 있었다.

소감
무엇보다 아쉬운점은 초반의 의욕과는 달리, 데이터사이언스 대회의 best practice를 실습해보지 못 했고, 제출과 점수에 급급한 채로 마무리 했다는 점이다. 시간 부족과 의사소통 부재로 EDA 깊이 있게 하지 못 했고, Hyperparameter tuning과 grid search를 제대로 시행하지 못 햇다.
마지막으로, 이번 원자력발전소 상태 판단 대회 참가는 데이터사이언스 관련 대회 경험을 쌓기 위해서였지만, 한편으로는 전혀 접하지 못 했던 원자력발전소 관련 데이터를 접하고 발전소 관련 도메인을 조금이나마 얻기 위함이기도 했다. 그러나 데이터셋의 컬럼은 모두 비식별 처리가 되어 있어 무엇을 의미하는지 데이터의 특성과 정보에 대한 접근이 불가했다는 점이 대회를 참가하는 와중에 흥미가 조금 깎이게 된 요인이 되지 않았나 하는 생각이 든다.
어쨌거나 저쨌거나 완주를 했고, 상위 10% 내 라는 기대도 하지 않았던 성적으로 마무리를 했기 때문에 여기에 의의를 두며, 다음에 참가하는 데이터사이언스 대회는 이번에 아쉬웠던 점들이 꼭 보완될 수 있도록 다짐을 해본다.