Machine Learning Operations(MLOps)에 대한 주제로 공부하며 기초를 정리해보았습니다.
1. ML VS Real-world ML
1.1. 학술, 연구, 대회, 개인 프로젝트에서의 머신러닝 프로젝트
일반적으로 머신러닝 프로젝트를 시작하거나 학술적인 연구를 하는 경우, 머신러닝 프로젝트는 아래와 같은 성향을 띄고 있음.

source: Udacity
- 해결하고자 하는 문제의 정의와 데이터셋이 주어져 있음.
- 프로젝트의 목적은 주어진 데이터셋을 기반으로 평가 메트릭에서 모델의 성능이 가장 높게 나오는 모델링을 실행하는 것
- 프로젝트 진행 동안 만족할만한 모델 성능이 나올 때까지 일련의 과정을 사이클로 반복함
- 데이터셋에 대한 탐구
- 여러가지 피쳐 엔지니어링 테크닉 적용
- 여러가지 하이퍼파라미터 조절
- 여러가지 머신러닝 알고리즘의 적용
1.2. 프로덕션까지 이어진 머신러닝 프로젝트
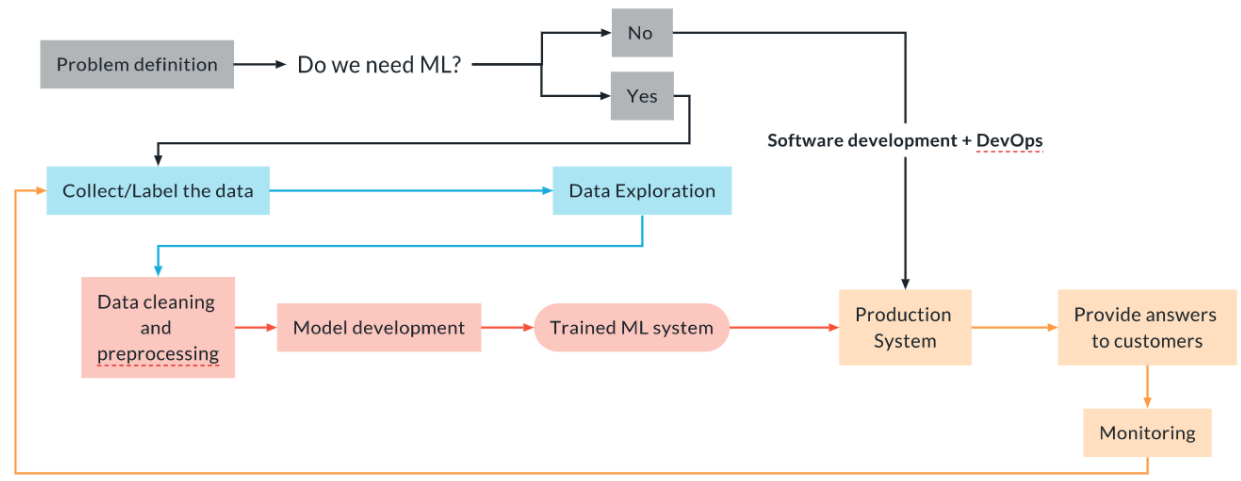
source: Udacity
- 실제 머신러닝 프로젝트에서는 머신러닝 모델이 프로덕션에서 사용되어지는 경우를 염두에 둬야 함.
- 해결하고자 하는 문제를 정의하고, 머신러닝 기법이 필요한지의 여부를 결정함.
- 머신러닝 기법이 필요하지 않은 경우도 있으며, 이 때는 굳이 머신러닝을 적용하지 않아도 됨. (~하지만 제품을 마케팅하기 위해, 과제를 따내기 위해, 투자를 받기 위해 등등 갖가지 이유로 기어코 머신러닝을 적용하는 방향으로 가는 경우도 있음~)
- 여러 경로를 통해 데이터를 직접 확보해야 함.
- 데이터 정제, 전처리, 모델링을 통해 모델을 구축하고, 실제 프로덕션 시스템에서 동작할 수있도록 배포할 수 있어야 함.
- 데이터 드리프트(data drift), 퍼포먼스 드리프트(performance drift) 등이 발생하는 경우에 대비해서 지속적인 모니터링과 모델 재학습의 사이클이 자리잡혀 있어야 함.
- 여러 팀원과 부서에서 협업할 수 있도록, 과정이 명확하고, 재현 가능해야 함.
2. MLOps의 등장
2.1. MLOps의 정의
- 미국의 정보 기술 연구 & 컨설팅 기업인 Gartner는 2020년 12월을 기준으로 47%의 인공지능 프로젝트가 제품화에 실패한다는 조사 결과를 밝힘.(링크)
- 이러한 결과는 대부분의 머신러닝 프로젝트가 상단에서 기술한 1.1. 에 기반을 두고 있어서 임을 유추해볼 수 있음.
- 따라서 실제 프로덕트에서도 머신러닝을 적용하고 유지할 수 있는 파이프라인에 대한 고민을 하게 되었고, MLOps라는 개념이 등장하게 됨.
- MLOps의 정의: 실제 프로덕션 환경에서 가장 효율적으로 높은 성능, 안정적, 재현가능, 확장가능, 자동화, 재사용성을 갖춘 머신러닝 파이프라인을 end-to-end로 구축하는 방법론
2.2. 성공적인 머신러닝 프로젝트가 되기 위한 조건
- (당연한 말이지만 1) 머신러닝으로 풀어야 하는, 풀 수 있는 문제 정의
- (당연한 말이지만 2) 목표와 기간 설정
- (당연한 말이지만 3) 충분한 데이터셋
- 프로덕션 환경에서 모델을 유지하기 위한 전략
- 한번 배포한 모델이 영원히 잘 동착할 거라고 장담할 수 없음.
- 프로덕션 환경을 늘 고려할 것.
- 머신러닝 프로젝트를 진행하는 과정에서 내리는 모든 의사결정은 프로덕션 환경에서 동작되는 시나리오를 고려하여 내려야 함.
2.3. MLOps를 적용해야 하는 환경
- 프로덕션 환경
- PoC(Proof of concept)이나 MVP(minimum viable product)를 위한 머신러닝 프로젝트인 경우에는 적용되지 않아도 됨.
- 모델의 재현, 재사용이 빈번하게 일어나는 경우
- 프로젝트의 문서화, 협업이 빈번하게 일어나는 경우
- 프로젝트의 구조가 복잡한 경우
- Model Drift가 발생하는 경우
- Data drift, Performance drift라고도 함.
- Data drift: 시간의 흐름에 따라 데이터의 특성이 달라질 경우
- Performance drift: 시간의 흐름에 따라 모델의 성능이 감소할 경우
- 대부분의 모델은 일정한 시점의 데이터셋을 기반으로 학습되었음. 따라서 새로운 데이터에 대해서는 안정적인 성능을 보이지 않을 수 있음.
- 이러한 경우를 대비한 시스템이 구축되어 있어야 함.
- 모델의 성능, 데이터의 특성 등에 대한 모니터링
- 새로운 데이터에 대한 EDA, 피쳐 엔지니어링, 하이퍼파라미터 튜닝, 모델 재학습과 같은 사이클
- Data drift, Performance drift라고도 함.
Reference
- Udacity: Machine Learning DevOps Engineer