1 쿠버네티스 개념 아키텍처
1.1. 개념
- 컨테이너화 된 어플리케이션의 배포, 확장, 운영을 자동화하기 위한 오픈소스 시스템
- 구글에 의해 개발됨.
- CNCF에 기반을 둠
1.2. 주요 특징
- 자동화된 롤아웃 및 롤백
- 어플리케이션 업데이트 시 롤아웃을 자동으로 관리
- 문제 발생 시 이전 버전으로 롤백
- 서비스 접근 및 로드 밸런싱
- 클러스터 내의 어플리케이션에 쉬벡 접근
- 트래픽을 자동으로 분산
- 스케일링
- 리소스의 사용에 따라 자동 또는 수동으로 스케일링
- 자체 회복
- 실패한 컨테이너 재시작.
- 건강하지 않은 컨테이너는 교체
- 준비되지 않은 노드로부터 어플리케이션 이전
2. 쿠버네티스 아키텍쳐와 주요 구성 요소
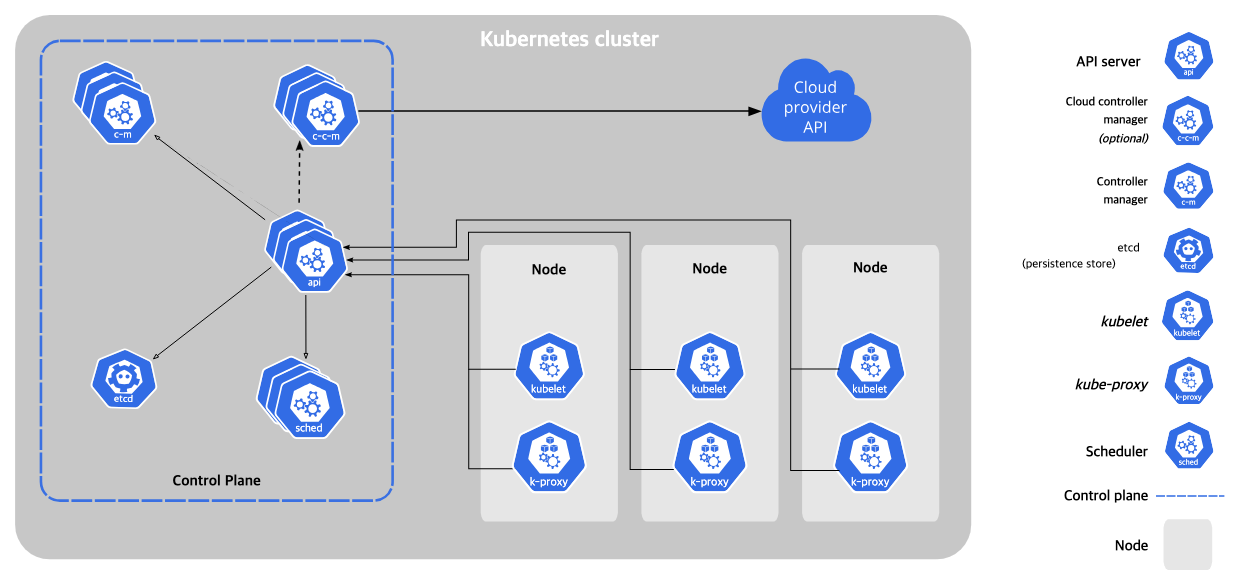
2.1. 아키텍처
- Master ← → Node 구조로 이루어진 클러스터를 사용
마스터 컴포넌트
- API 서버 (kube-apiserver): 쿠버네티스 API를 제공하며, 사용자와 내부 컴포넌트 간의 중재자 역할을 함
- 스케줄러 (kube-scheduler): 새로 생성된 파드를 어떤 노드에 할당할 지 결정
- 컨트롤러 매니저 (kube-controller-manager): 여러 컨트롤러를 실행. 노드 컨트롤러, 레플리케이션 컨트롤러 등이 존재함
- etcd: 모든 클러스터 데이터를 저장하는 경량의 분산 키-값 저장소
노드 컴포넌트
Pod가 할당되어 있는 공간
- kubelet : 각 노드에서 실행되며, 파드 스펙(Spec)에 설명된 대로 컨테이너가 실행되고 있는지 확인
- kube-proxy: 각 노드의 네트워크 규칙을 관리하여 네트워크 통신을 가능케 함
- 컨테이너 런타임: 컨테이너 실행을 담당하는 소프트웨어 (Docker, containerd, CRI-O 등)
2.2. 기능
- 클러스터 구성
- 먼저 쿠버네티스 클러스터를 구성.
- 클러스터는 여러 노드 (물리적 또는 가상머신)와 이들을 관리하는 마스터 노드로 구성됨
- etcd 는 클러스터 관리에 사용되는 모든 데이터를 분산된 Key-Value 형태로 저장함. 마스터 간 충돌이 없도록 클러스터 내에서 잠금을 구현함.
- API 서버와의 통신
- 사용자는 kubectl CLI 또는 API를 통해 API 서버와 통신함
- 이를 통해 파드의 생성, 업데이트, 삭제 등의 작업을 요청함
- 스케줄링과 실행
- 스케줄러는 새로운 파드에 대해 가장 적합한 노드를 선택함.
- kubelet은 해당 노드에서 파드의 컨테이너가 예상대로 실행되도록 관리함.
- 서비스 관리
- kube-proxy는 서비스를 통한 네트워크 트래픽을 관리.
- 서비스는 파드 그룹에 안정적인 접근성을 제공함.
- 자동화된 롤아웃 및 롤백
- Deployment를 통해 어플리케이션의 업데이트, 롤아웃 및 롤백을 자동으로 관리함
- 스케일링과 자체 치유
- 어플리케이션의 수요에 따라 자동으로 스케일링함.
- 실패한 파드를 재시작 하는 등의 자체 치유 기능을 제공함.
2.3. 주요 구성 요소
2.3.1. Pod
개념
- 쿠버네티스에서 배포할 수 있는 가장 작은 작업 단위
- 하나 이상의 컨테이너를 포함할 수 있으며, 이들은 스토리지와 네트워크를 공유
- 공유해야한다면 하나의 파드에서 구동시키는 것이 적합함
특징
- 컨테이너 그루핑:
- 하나 이상의 밀접하게 관련된 컨테이너를 그룹화
- 이 컨테이너들은 같은 컴퓨팅 리소스를 공유함
- 공유 리소스
- 파드 내 컨테이너는 같은 IP 주소와 포트공간을 공유함
- 서로 localhost를 통해 통신
- 일시적인 성격:
- 파드는 일시적.
- 파드가 삭제되면 그 안의 컨테이너도 함께 삭제됨
- 따라서 파드는 변경 가능한 리소스로 간주됨.
- 생명주기:
- 파드는 생성되고, 실행되고, 종료될 때 까지의 생명주기를 가짐.
- 파드가 종료되면, 쿠버네티스 클러스터에서 제거됨
사용 예
- 단일 컨테이너 파드: 대부분의 파드는 하나의 컨테이너만을 실행함
- 멀티 컨테이너 파드: 로깅, 데이터 백업, 데이터 처리와 같은 보조 기능을 수행하는 사이드카(sidecar) 컨테이너를 함께 포함하는 경우
2.3.2. Service
개념
- 서비스는 파드의 집합에 대한 안정적인 네트워크 주소를 제공함
- 서비스를 통해 파드 집합에 대한 접근을 관리하고, 로드 밸런싱 및 서비스 발견이 가능함 (service discovery) → 그냥 서비스 디스커버리라고 하면 되지, 자꾸 서비스발견 서비스발견 거려서 뭔말인가 했네
특징
- 안정적인 주소 제공: 서비스는 파드 집합에 지속적으로 접근할 수 있는 안정적인 IP주소와 포트를 제공함
- 로드 밸런싱: 서비스는 요청을 여러 파드에 분산시켜 로드 밸런싱을 수행함
- 서비스 발견: Service Discovery
- 서비스 타입: 다양한 서비스타입을 통해 다양한 네트워크 요구사항을 충족함
- ClusterIP
- NodePort
- LoadBalancer
- ExternalName
사용 예
- ClusterIP: 클러스터 내부에서만 접근 가능한 서비스를 만들 때 사용
- LoadBalancer: 클라우드 제공 업체의 로드밸런서를 사용하여 서비스에 대한 외부 접근을 관리할 때 사용
2.3.3. Deployment
개념
- 쿠버네티스에서 파드와 레플리카셋의 상태를 선언적으로 관리하는 API 오브젝트
- 어플리케이션의 배포, 업데이트, 스케일링 등을 자동화 하고 관리함
특징
- 자동화된 롤아웃과 롤백: 새로운 버전을 롤아웃하고 필요한 경우 이전 버전으로 롤백하는 프로세스를 자동화
- 상태 관리: 원하는 상태 (Desired State)를 정의하고, 쿠버네티스가 현상태(Current State)를 앞서 정의한 상태대로 유지함
- 선언적 업데이트: YAML 파일이나 JSON 형식을 사용하여 애플리케이션을 업데이트하는 방식을 선언함
- 스케일링: 파드의 수를 수동 또는 자동으로 조절하여 애플리케이션을 스케일링함
사용 예
- 새 버전 배포
- 스케일링: kubectl scale deployment 명령어를 사용하여 확장하거나 축소
2.3.4. ReplicaSet
개념
- 레플리카셋은 파드의 복제본을 유지 관리하는 쿠버네티스 오브젝트
- 파드의 원하는 복제본 수를 지정함
- 지정된 수의 파드 복제본이 항상 실행되고 있도록 보장함
특징
- 복제본 수 관리: 지정된 수의 파드 복제본을 유지함
- 자체 치유: 실패한 파드를 자동으로 대체하여 복제본 수를 유지함
- 유연한 파드 선택: 레이블 선택기(Label Selector)를 사용하여 관리할 파드를 결정함
사용 예
- 어플리케이션 가용성 보장: 레플리카셋은 어플리케이션의 가용성을 높이기 위해 여러 파드의 복제본을 두고 실행함.
- 부하 분산: 덕분에 트래픽이 분선되고 부하가 복제본에 균등하게 분배됨.
2.3.5. StatefulSet
개념
- Stateful한 pod를 관리하기 위한 controller.
특징
- pod들의 고유성과 순서를 보장함.
사용 예
- 마스터 노드가 가동된 후 순차적으로 워커 노드가 가동되어야 하는 경우를 보이는 database.
- Persistent Volume(PV)을 개별 포드로 생성하여 연결함. Pod가 비정상적으로 종료된 경우에도, 새로운 Pod가 PV를 담당함.