최근에 VectorDB 라는 키워드를 접하고 훑어보다, Vector Database → RAG (Retrieval Augmented Generation) → LangChain 의 흐름으로 연관이 있음을 알게 되었고, RAG 튜토리얼을 간단하게 따라해보았다.
참고 튜토리얼 - LangChain: QnA with RAG
테니스GPT
챗GPT가 처음 등장했을 때, 테니스 관련해서 이것저것 물어보며 가지고 놀았던 기억이 있어, 튜토리얼을 기반으로 테니스와 관련된 아주 간단한 QA애플리케이션을 만들어보면 어떨까 했다.
전처리
Loader
테니스와 관련된 문서를 그 자리에서 간략하게 수집했다. 위키파일도 있으며, 동호인 웹사이트에 존재하는 문서도 있기에 모두 txt 파일로 저장했다.
Text Splitter
Text Splitter의 경우 그대로 RecursiveCharacterTxtSplitter 를 사용했다. Chunk가 충분히 작아질 때까지 단락, 문단, 문장, 단어 순으로 split을 반복 시도하는, 가장 범용으로 사용되는 splitter이다.
Embedding
Embedding의 경우 가장 가성비가 좋은 text-embedding-3-small을 사용했다. 디폴트가 가성비가 더 안 좋은 text-embedding-ada-002-v2 인 것을 나중에 알았다. (pricing 참고)
Vector Database
Vector DB 는 FAISS를 사용해보았다. 튜토리얼의 흐름에서는 애플리케이션이 실행될 때마다 문서 인덱싱을 새로 하게 되는 것 같아서, 사전에 생성된 인덱스를 로컬에 저장하고 애플리케이션 실행 시 로드하도록 했다.
Retrieval & Generation
Prompt
프롬프트 템플릿으로는 튜토리얼에서도 사용되었고 가장 보편적인 형태를 보이는 rlm/rag-prompt 를 사용했다. (이 기회에 LangSmith도 경험이 되었다.)
You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}`
Context: {context}`
Answer:
LLM Model
LLM모델은 OpenAI의 gpt-3.5-turbo, gpt-4-turbo-preview 두가지 모두 사용해보았다. 아무래도 gpt4 가 한국어 생성 측면에서 전자에 비해 더 매끄럽고 자연스러웠다. 과금은 좀 더 비싸지만.
Application
애플리케이션 프레임워크로는 Streamlit을 사용해서 정말 최소x3의 형태로 만들었다.
ChatGPT-3.5와의 비교
동일한 프롬프트를 적용하고, ChatGPT에서는 context에 해당하는 retrieval output을 제외하고 동일한 질문을 했을 때 출력되는 답변을 비교 해볼 수 있다. (** 참고로 RAG에 쓰인 텍스트 데이터의 시점은 ChatGPT와 거의 동일한 2021년이다.)
- 테니스 단체 정보
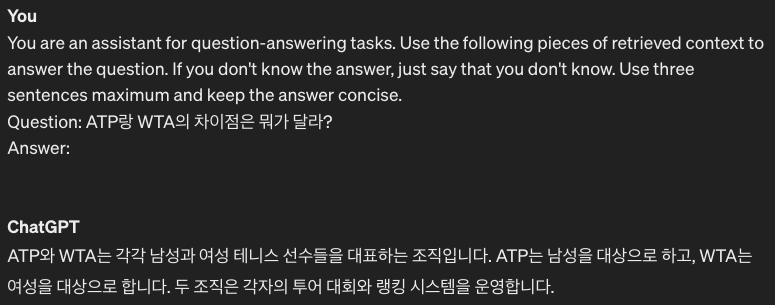

- 2024년 마지막이 될 것 같은 전설 같은 선수, 라파엘 나달에 관한 정보.
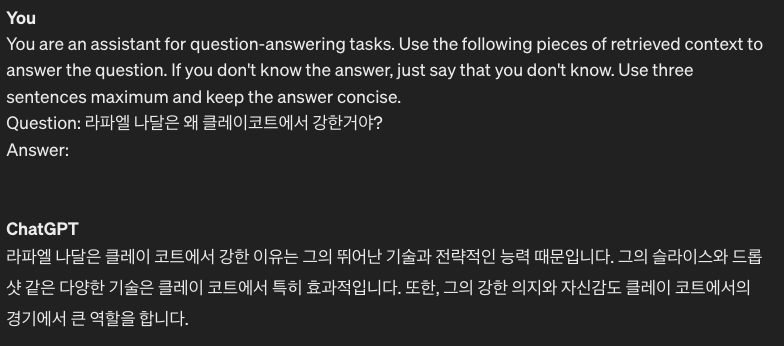
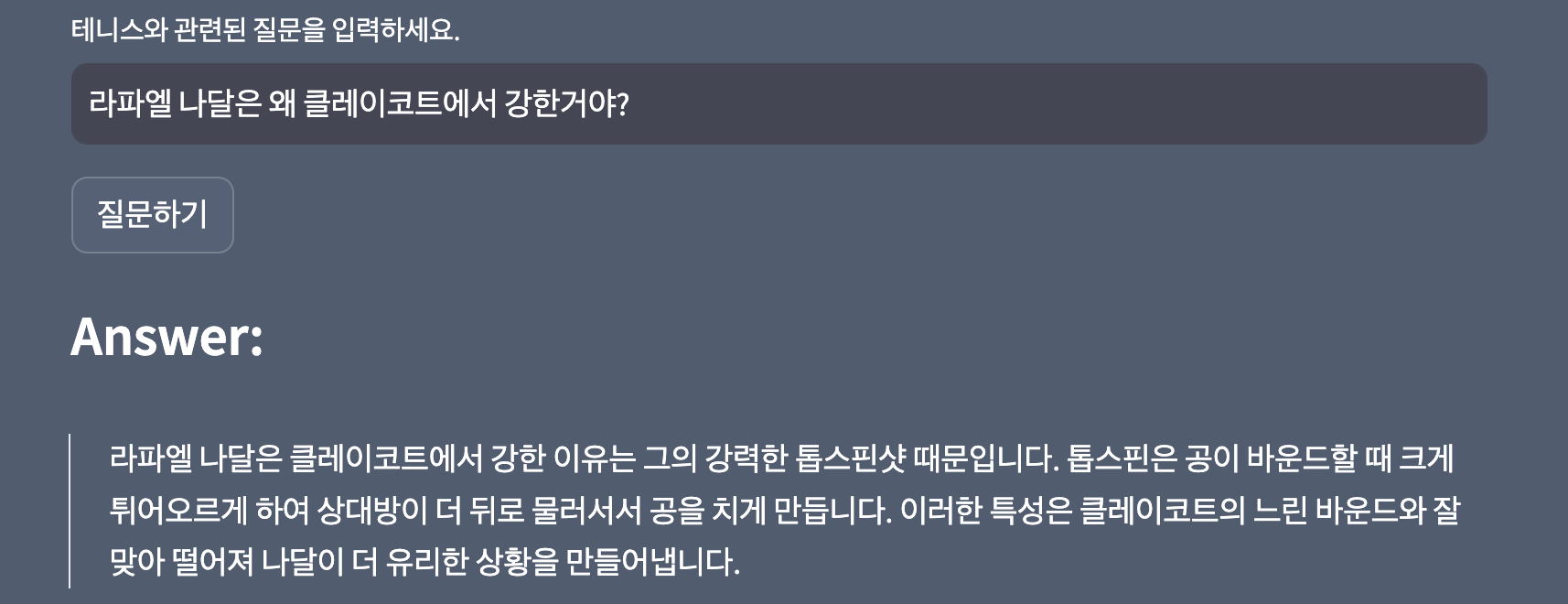
- 동호인 대회 나가서 가장 스트레스 받는 점
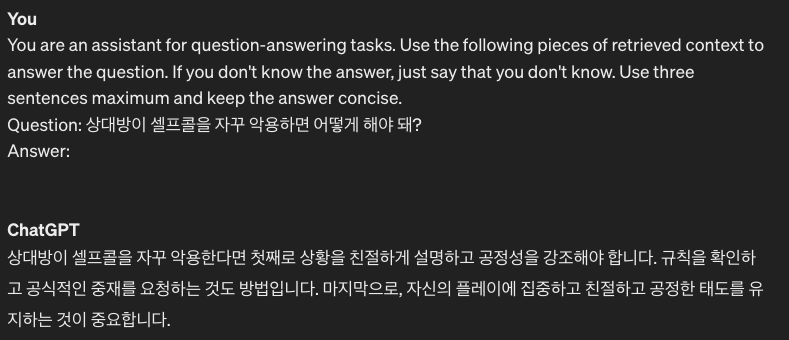
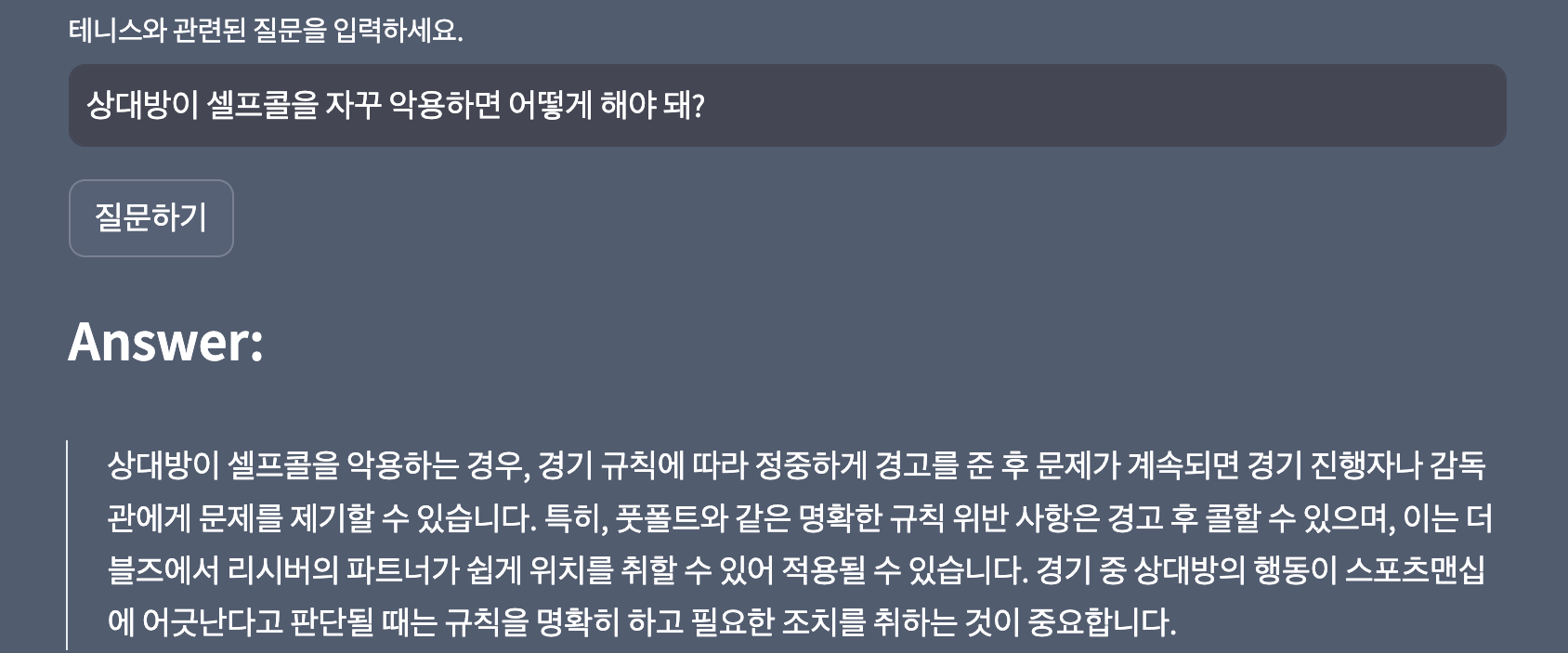
- 테린이 최대 관심사 중 하나


AI 또는 LLM에 대한 배경지식 없는 테니스 동호인이 실제로 사용한다고 가정했을 때, ChatGPT는 다소 두루뭉술한 답을 한다. 반면에 RAG로 구축한 Q&A 애플리케이션은 같은 질문에 대해서 훨씬 직접적이고, 간결한 답을 구사한다고 판단할 수 있다. 마지막 코트 예약과 관련된 질문에 대해서 ChatGPT는 아주 일반적인 대답을 지어낸 반면, RAG 기반 애플리케이션에서는 할루시네이션 없이, 제공된 정보가 없다고 답했다. ( 역시 코트 예약은 … 빠르게 … 잘 … 정직하게 … )
애초에 동작하는 방식과 목적, 적용 방안이 다르기에 직접적인 비교는 무리가 있지만, 제너럴한 답변을 하는 ChatGPT와, VectorDB에 인덱싱 된 문서로부터 답변을 추출한 RAG 사이 이 정도 차이점이 있다는 것을 확인할 수 있었다.
RAG 찍먹 후기
- 랭체인을 활용한 RAG는 정말이 너무 간편했다. 간편함을 레버리지 삼아. 퀄리티를 높일 수 있는 고민거리에 시간과 에너지를 더 사용할 수 있을 것 같다.
- 가장 간편한 텍스트의 형태의 데이터만 사용했지만, 실무에서는 다양한 형태의 문서, 특히 이미지와 표가 함께 섞여 있는 PDF 같은 데이터를 “제대로”, “잘” 파싱하는 것이 실무에서는 매우 중요할 것 같다.
- Text Splitter - 실무를 한다면 어떤 것을 사용할 지, 이 부분이 가장 고민 될 것 같고, 실험을 많이 해봐야 할 것 같다. 가장 기본적으로 사용해볼 수 있는
CharacterTextSplitter,RecursiveCharacterTextSplitter만 비교해서 사용해봤으나, HuggingFace의 토크나이저까지도 고려대상이 될 수 있을 것 같다. - 가장 기본적으로 OpenAI의 Embedding을 사용했으나, 나중에는 과금의 요소를 무시하지 못 할 것 같다. (현재의 가격도 PoC나 토이프로젝트 레벨에서는 그리 부담되는 정도는 아니긴 하다.) 더 찾아보니 CashBackedEmbedding 을 통해서 동일한 임베딩의 경우에는 캐싱이 가능해 속도가 빠르고, 중복 과금을 피할 수 있다고 하니 이 부분은 기본으로 장착 하는 것이 좋아보인다.
- 결과적으로 약간의 과금을 감수하고서라도, 간편함과 가벼움에 이점이 있어서 OpenAI의 임베딩과 모델을 사용했다. Huggingface 모델도 사용해보려 했으나, 현재 자원에서 모델 로드 자체가 제한적이었다. (Colab에서도 모델의 사이즈 때문에 로드가 되지 않더라.) 인프라가 뒷받침이 된다면 HF에서 여러가지 모델을 실험, 비교해볼 수 있을 것 같다.